Prompt Bench
How we train the prompts that power our agents

How do you know the prompts your agents are running today are better than the ones they ran last week?
Maybe it's a gut feeling. Maybe the results look better. Maybe you ran some data through them and they seemed fine.
The GTM Engineering team at Vercel owns a lot of agents. Two of them digest most inbound leads our teams field. Lead Agent has classified thousands of leads. MQL Agent has qualified many times that in the same period. At that scale, gut feelings and good looks don't cut it.
We built Prompt Bench: a platform for evaluating and monitoring the prompts that power our agents.
Use cases
Not every prompt does the same thing, and you can't evaluate them the same way. Prompt Bench handles three types:
- Classification--Should this go to sales, support, or neither? Binary or multi-class decisions broken down per category.
- Generation--Draft a reply email. Write a personalized outreach message. Scored by an agentic judge against a rubric--brevity, tone, personalization, formatting.
- Extraction--Pull structured fields from unstructured input. Each field validated independently, from exact matches to fuzzy semantics.

Each type gets its own evaluator. A misclassified lead and a stiff email are different kinds of wrong.
Lineage
Every prompt belongs to a lineage--a versioned family scoped to a use case and model. Each iteration is tracked: system prompt, user template, the works. When something breaks, you can diff the current version against the previous one and see exactly what changed.
If this sounds obvious, it isn't. Most prompt work happens in notebooks, playgrounds, or Slack threads. The prompt that's running in production is whatever someone last deployed. Lineage makes every version a first-class artifact.
Test sets
Every prompt looks good against the examples you wrote it for. We gather test sets from many sources. For example:
- Production samples--Real leads that our pipelines already assessed. The production decision along with human verification becomes the expected output. This is the ground truth that matters most.
- Synthetic cases--Cases generated from seed examples to fill gaps. Edge cases, unusual domains, tricky formatting. Fuzzy deduplication prevents overlap with existing cases.
- Team-raised cases--Real-world results flagged by our GTM teams. Sometimes it's “that's wrong”--sometimes it's “that's exactly right, protect it.”
Experiments
Run a test set against a prompt and every case comes back with expected vs. actual, broken down by decision category. We're able to diff and pinpoint exactly where the prompt got it wrong.
This is where the work gets interesting. Every prompt change has consequences you can only see with data. Fix false positives and accuracy goes up, but deferred cases start falling through. Tighten one category and another gets confused. Each version is a hypothesis. The test run is the experiment. Over time, the experiments compound and the prompts get measurably better.
Monitoring
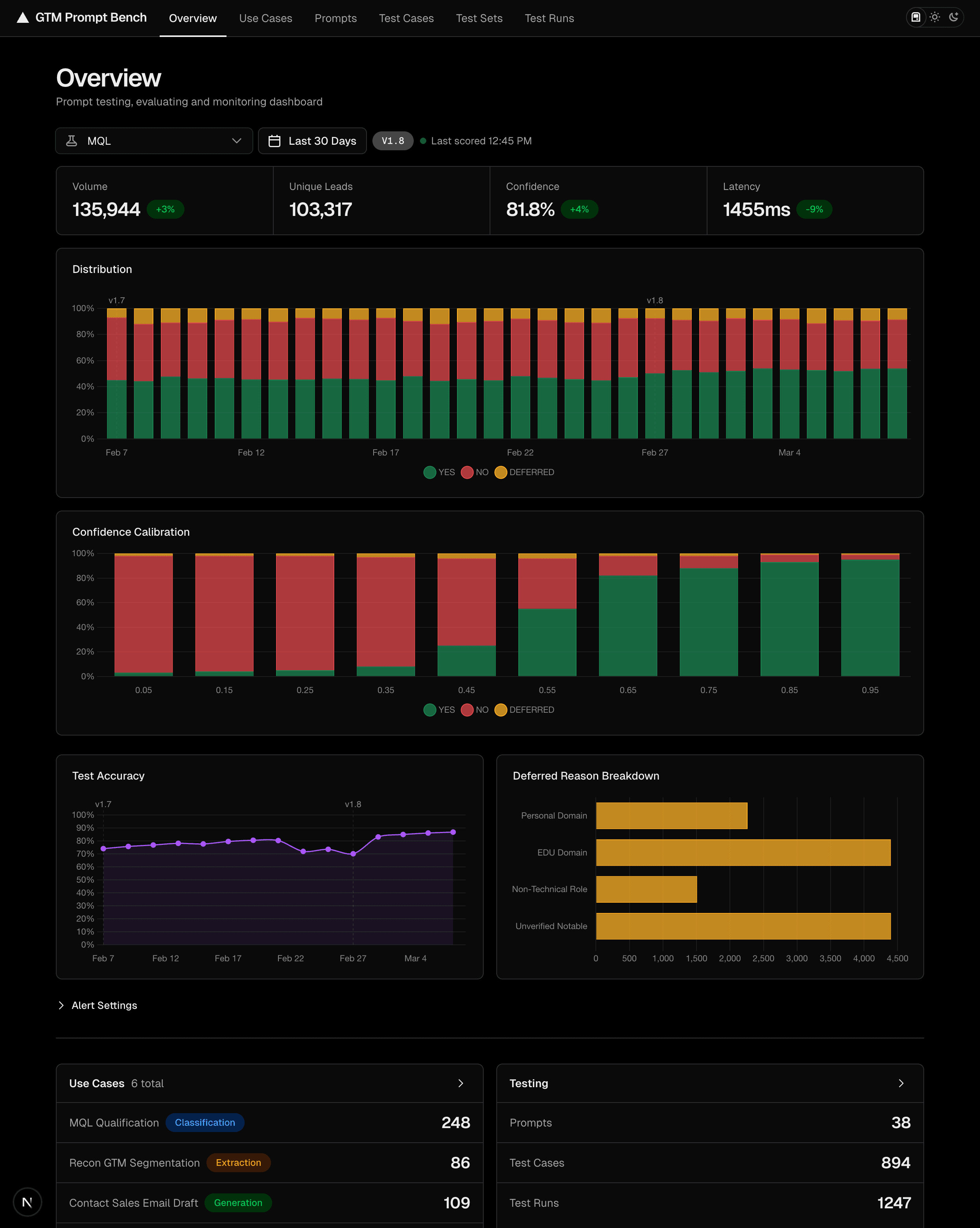
dashboard shown with sample data
Testing prompts on historical data tells you what to expect. But what's critical is knowing when to step in. Prompt Bench monitors our production pipelines in real time--decision distributions, confidence trends, deferred reasoning. When metrics drop below our targets, alerts fire everywhere. A dip in one of our accuracy charts told us it was time to retrain the prompt before it ever affected the pipeline.
Prompts are production code that affects revenue. Prompt Bench is how we train them.

Illustrations by Jon Romero Ruiz.